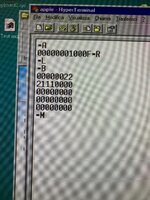
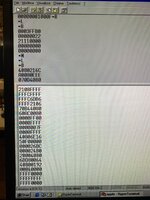
Dissecting the stack from the start:
The return address from InitADB, meaning InitADB was started but never completed.
Code:
2000 Status Register
40806DD8 Program Counter
0064 Exception vector offset (Level 1 interrupt)
The stack frame for a level 1 interrupt generated by the VIA.
The interrupt was triggered while this infinite loop was running waiting for ADB initialization to finish:
Code:
40806DD4: andi #$F8FF,SR
.Loop:
40806DD8: btst.b #ADBInit,(ADBFlag,A3)
40806DDE: bne.b .Loop
The VIA interrupt handler then saves registers to the stack to restore later:
Code:
0000FF00 = D0
0000FFFF = D1
0000007F = D2
0000FFFF = D3
40806E16 = A0 (An ADB routine that was installed in another piece of code)
50F00000 = A1 (VIA address)
000026DC = A2
000024B0 = A3
The current MMU 24/32-bit mode value is saved on the stack:
Next it runs the proper interrupt handler based on the interrupt register from the VIA:
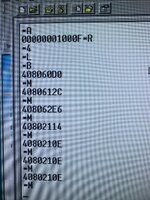
Right after that is the stack frame for the bus error. It was likely modified a bit by the error handler but this should be the reconstruction:
Code:
2111 Status Register
00000022 Program Counter
A008 Short bus cycle, bus error
0EEE Internal Register
070D Special Status Word (Longword write data fault)
40802108 Next two bytes of the instruction pipe
FFFFFFFC Fault Address (Location to write to)
FFFF Internal Register
FFFC Internal Register
6DB6FFFF Output Data (Data to write)
2106 Internal Register
70B4 Internal Register
This tells us there was bus error on the boundary of 0x22, supposedly attempting to write the longword 0x6DB6FFFF to address 0xFFFFFFFC.
Here is what the exception vectors likely look like in low memory at the moment:
Code:
08: 408020FA
0C: 408020FC
10: 408020FE
14: 40802100
18: 40802102
1C: 40802104
20: 40802106
24: 40802108
The last three vectors can technically be interpreted as code:
Code:
1C:
negx.l D0
move.l D4,-(A0)
20:
negx.l D0
move.l D6,-(A0)
24:
negx.l D0
move.l A0,-(A0)
If A0 contained 0x00000000 and it tried to execute
move.l D6,-(A0), A0 would be decremented and underflow to 0xFFFFFFFC. I believe that address is one of the autovector, which should only be generated during an interrupt along with /AVEC. I assume either the processor does not allow this write or the GLUE logic never acknowledges it without /AVEC being asserted.
The thing I still haven't figured out is how it's ending up executing code there in the first place. I'm guessing it's running the ADB interrupt handler, but that's not a short routine so I'm not sure where it is in there.
If you can I would suggest checking areas around the VIA and ADB chips, check the traces between the two, etc.



")