Hi everyone,
I want to adapt and expand the logic of the TS Mercury RAM expansion board into an SRAM controller. My goal is to ensure a 4MB 32-bit SRAM bank works correctly with these accelerator boards. At the same time, I am exploring if the Accelerator/SRAM logic could handle a 31.33 Mhz clock.
If I succeed, then the MicroMac Performer logic could be upgraded, and we would have an open-source accelerator for the Plus/SE with 4MB of fast RAM hopefully working at 31.33 MHz with a 33MHz 68030 CPU!
To keep things simple and robust, the controller operates in asynchronous mode (just like the original RAM expansion board), using three full clock cycles for data access and, hopefully, 0-wait states. This is my first attempt at recreating an SRAM controller for these accelerators, so I’m applying everything I’ve learned since I started fiddling with them!
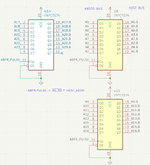
The main logic is split across three PLDs:
RU6: Primarily an address decoder, nearly identical to the original logic.
RU7: Handles SRAM access using standard 68030 dynamic bus sizing logic.
RU8: Functions as the state machine for the 68030 bus handshake.
I’ve drafted the logic equations for these three chips and would love a "sanity check" from the 68030 architecture gurus here.
RU6: Address Decoder
This chip maps the accelerator's local SRAM and isolates it when the CPU attempts to access the video buffers on the system RAM.
DBFR_OE: This signal controls the 74245 data buffers, asserting LOW to enable the SRAM bus path.
RU7 maps the 32-bit bus to four 8-bit SRAM banks (/BYTE1 through /BYTE4). It follows the 68030 transfer bus sizing standard, using SIZ0/SIZ1 and A0/A1 to enable the correct byte lanes for aligned or unaligned transfers.
RU8: The State Machine (Timing Core)
This is the heartbeat of the memory controller and, as expected, is a much simpler state machine than the original DRAM controller. It is configured as a Registered PLD to handle timing and asynchronous handshaking via DSACK signals.
Is there a better way to obtain this synchronized 31.33MHz signal, or does this "GAL-frequency multiplier" approach seem feasible? How about a PLL-based Clock Generator?
I have attached the full schematics and EQN files below. Any feedback, tips, or "gotchas" are more than welcome before I order the first PCB prototype!
I want to adapt and expand the logic of the TS Mercury RAM expansion board into an SRAM controller. My goal is to ensure a 4MB 32-bit SRAM bank works correctly with these accelerator boards. At the same time, I am exploring if the Accelerator/SRAM logic could handle a 31.33 Mhz clock.
If I succeed, then the MicroMac Performer logic could be upgraded, and we would have an open-source accelerator for the Plus/SE with 4MB of fast RAM hopefully working at 31.33 MHz with a 33MHz 68030 CPU!
To keep things simple and robust, the controller operates in asynchronous mode (just like the original RAM expansion board), using three full clock cycles for data access and, hopefully, 0-wait states. This is my first attempt at recreating an SRAM controller for these accelerators, so I’m applying everything I’ve learned since I started fiddling with them!
The main logic is split across three PLDs:
RU6: Primarily an address decoder, nearly identical to the original logic.
RU7: Handles SRAM access using standard 68030 dynamic bus sizing logic.
RU8: Functions as the state machine for the 68030 bus handshake.
I’ve drafted the logic equations for these three chips and would love a "sanity check" from the 68030 architecture gurus here.
RU6: Address Decoder
This chip maps the accelerator's local SRAM and isolates it when the CPU attempts to access the video buffers on the system RAM.
DBFR_OE: This signal controls the 74245 data buffers, asserting LOW to enable the SRAM bus path.
- Video Buffer “Hole”: The logic monitors A23-A15 and FC0/FC1 to detect the address range of the Mac Plus video buffer (the top 32KB of the first 4MB space).
- RAM Routing: When access is detected within the $3F8000 - $3FFFFF range, the SRAM buffers are disabled and access is routed back to the main accelerator logic to handle the motherboard RAM. It also ignores Function Codes associated with interrupts or non-standard states to keep the bus clean.
RU7 maps the 32-bit bus to four 8-bit SRAM banks (/BYTE1 through /BYTE4). It follows the 68030 transfer bus sizing standard, using SIZ0/SIZ1 and A0/A1 to enable the correct byte lanes for aligned or unaligned transfers.
RU8: The State Machine (Timing Core)
This is the heartbeat of the memory controller and, as expected, is a much simpler state machine than the original DRAM controller. It is configured as a Registered PLD to handle timing and asynchronous handshaking via DSACK signals.
- Wait States: It reads two jumper inputs (WS1, WS2) to allow configuration of 0, 1, or 2 Wait States.
- Delay Logic: It uses internal registered feedback nodes (rf17 -> rf16 -> rf15) to create a shift-register style delay triggered when /SELECT goes low.
- 0WAIT Performance: I have 45ns SRAM ICs (CY62158H) on hand, so 0-WAIT should be achievable with a 16MHz clock. For a 32-bit port, the 68030 requires both DSACK0 and DSACK1 to be asserted; RU8 drives both pins low simultaneously.
- Write Enable: It generates /SRAM_WE only when RW is low, AS is active, and the block is selected.
Is there a better way to obtain this synchronized 31.33MHz signal, or does this "GAL-frequency multiplier" approach seem feasible? How about a PLL-based Clock Generator?
I have attached the full schematics and EQN files below. Any feedback, tips, or "gotchas" are more than welcome before I order the first PCB prototype!
Attachments
Last edited: